Generative Engine Optimisation (GEO) is the discipline of improving how often—and how prominently—your content is selected, quoted, cited, and linked inside AI-generated answers produced by “generative engines” (AI systems that retrieve information from sources and synthesise a response, often with citations). In contrast to classical SEO (ranking a page in a list of links), GEO targets visibility within the answer itself
A key reason GEO matters: as generative summaries and answer engines expand, users frequently get what they need without clicking through. In a large behavioural analysis, users encountering an AI summary clicked external links less frequently (8% of visits with a summary versus 15% without) and ended sessions more often (26% versus 16%).
The most rigorous formalisation of GEO to date proposes: (i) treating the generative engine as a black box you cannot control, (ii) defining visibility metrics tailored to citation-rich answers, and (iii) iteratively modifying content to improve those metrics. The same work introduces GEO-bench (10k-query benchmark) and reports that simple content changes—especially adding citations, quotations, and statistics—can improve visibility by up to ~40% on their metrics, while “SEO-like” keyword stuffing performs poorly.
For operational teams, the most useful way to think about GEO is as two overlapping playbooks:
This report is intentionally cloud-provider-agnostic and stack-agnostic. Any organisation-specific details (industry constraints, risk tolerance, budgets, latency targets, existing CMS/analytics, preferred LLM provider) are unspecified and therefore handled as decision points rather than assumptions.
Best practices (high-leverage, broadly applicable)
First, instrument visibility: define what “being cited” means for your business (e.g., citation share-of-voice, qualified referral traffic, or conversion uplift) and create a reproducible evaluation prompt set.
Second, optimise for “justify-ability”: content that contains clear claims, attributable evidence, and concise quotable passages is more likely to be used as support in answer generation.
Third, operationalise improvements as an experiment loop: variant generation → controlled testing → metrics → iteration.
Common pitfalls
Assuming SEO tactics transfer one-to-one (keyword stuffing can underperform in GEO settings).
Measuring “rank” instead of in-answer visibility (citations, prominence, and utilisation) in generative experiences.
Scaling content changes without governance (privacy, compliance, and safety can be violated by over-automation).
Decision criteria (what to choose first)
If you rely on search traffic and brand demand: tier 1 is measurement + content evidence improvements (citations/quotes/stats + structure).
If you ship an internal assistant: tier 1 is grounded RAG + evaluation/monitoring before model tuning.
Working definitions
A generative engine is a search/answer system that uses generative AI to produce a synthesised response, typically after selecting and corroborating information from retrieved sources. In one official description of such systems in search, the engine is explicitly framed as combining a customised generative model with existing search quality/ranking systems, surfacing information backed by top results, and providing links to supporting content.
Generative Engine Optimisation (GEO) is the creator-centric optimisation paradigm aiming to maximise a website’s visibility/impression in generative engine responses using a black-box framework and specialised visibility metrics.
Two scopes that are often conflated
External GEO and internal GEO share techniques (e.g., grounding, citation discipline, structured content), but differ in what you can control:
This distinction matters because external GEO leans heavily on content engineering and authority signals, while internal GEO is closer to information retrieval + ML engineering + platform reliability.
Relationship to SEO
Traditional SEO optimises for ranking in a link list. GEO optimises for selection and attribution inside a generated answer, where the engine may synthesise from multiple sources and quote/cite selectively.
Best practices
Define “visibility” in measurable terms (citations, prominence, attributable wording share, qualified downstream actions) before changing content.
Separately document your external and internal GEO goals; mixing them produces mismatched metrics and wasted iterations.
Common pitfalls
Treating “more mentions” as always good: you need correct mentions, correct context, and business-relevant queries.
Ignoring how bots access your site (crawl permissions, indexing, and user-triggered fetch paths affect whether you can be surfaced at all).
Decision criteria
If you cannot reliably observe citations/mentions today, prioritise measurement instrumentation ahead of content rewriting.
Why GEO emerged
The motivation is a structural shift from “ten blue links” to AI-mediated answers. From the producer side, this can mean fewer outbound clicks even when your content is used. Behavioural evidence shows fewer clicks when AI summaries appear and higher rates of session termination without a click.
Scale signals: growth of generative experiences in search
One official explainer describes AI Overviews/AI Mode as designed for complex, multi-step information journeys, combining generative models with existing search systems and surfacing corroborated results with links. It also describes “query fan-out” in AI Mode: issuing multiple related searches concurrently across subtopics and sources, then synthesising results.
Formal academic framing of GEO
The foundational GEO work argues the creator economy risks disadvantage because generative engines mediate exposure, and proposes a black-box optimisation framework plus dedicated visibility metrics.
Evidence that “classic SEO moves” do not automatically transfer
In controlled experiments, keyword stuffing is explicitly reported as non-performing relative to other GEO methods, while adding citations/quotes/statistics performs strongly.
Best practices
Treat GEO as a new optimisation target with its own objective function (visibility-in-answer) rather than as a rebrand of SEO.
Enforce “user-intent coverage” over single-keyword targeting, because generative engines often rewrite/expand queries via multi-search strategies (e.g., fan-out).
Common pitfalls
Chasing “AI traffic” without segmenting query intent (informational vs transactional vs support) leads to vanity visibility or unqualified sessions. The GEO benchmark explicitly categorises diverse query intents; use that mindset internally.
Overgeneralising from one engine’s behaviour: real systems differ in sourcing, stability, and bias patterns (a central claim of empirical comparative GEO analysis).
Decision criteria
If your business value requires off-platform conversion, prioritise GEO tactics that increase qualified clicks and brand trust, not just citations.
This section is written to support both external and internal GEO. Where details vary by engine/provider, that variability is unspecified and treated as a risk factor.
Reference architecture (retrieval → synthesis → attribution)
Generative engines generally combine:
A practical, engine-agnostic flow:

Algorithms and models you should expect (internal GEO lens)
External GEO implications
Because many engines corroborate with “top results” and integrate ranking/quality systems, your content must be (i) retrievable, (ii) interpretable in small chunks, and (iii) defensible as supporting evidence.
Best practices
Engineer for fan-out: produce content that answers a topic through decomposable subquestions (definitions, trade-offs, steps, edge cases), since engines may issue multiple related searches and then synthesise.
Write for cite-able evidence: provide attributions, clear claims, and stable facts that can be quoted within short context windows.
Common pitfalls
Assuming the engine reads your whole page: in practice, engines operate on retrieved chunks/snippets and may ignore context outside the selected passages (hence the importance of chunk-local clarity).
Treating citations as cosmetic: in GEO, citations are often the measurable unit of visibility.
Decision criteria
If you control the engine: prioritise retrieval quality, grounding discipline, and evaluation pipelines before model tuning.
If you do not control the engine: prioritise content structure and evidence density, and treat everything else as probabilistic.
This section synthesises the most defensible tactics from the GEO research literature and aligns them to a practical “what to do on Monday” workflow. When something depends on vertical, brand, or risk tolerance, it is explicitly flagged as unspecified.
GEO as black-box optimisation
The foundational GEO framing explicitly assumes you cannot modify or inspect proprietary engines. You can only modify your content and observe changes in visibility metrics, iterating accordingly.
Visibility is multi-dimensional
The GEO work’s metrics split visibility into objective “how much/where you appear” and subjective “how influential/valuable the citation feels,” operationalised via sub-dimensions such as relevance, influence, uniqueness, diversity, perceived prominence, and click likelihood.
A controlled study evaluates nine GEO methods and reports that the strongest, low-effort methods include adding citations, quotations, and statistics; meanwhile, keyword stuffing is non-performing.
A practical mapping of those methods into an editor/engineering workflow:
Make content machine-scannable and chunk-stable
Generative systems often select evidence at passage-level. Use headings that answer common subquestions, and keep key definitions close to the heading (within the same chunk). This aligns with the way RAG pipelines feed retrieved context + query into the model.
Add structured data where it represents the main content
Structured data is widely used by search systems; general guidelines stress accuracy, representativeness, crawlability, and non-misleading markup, and explicitly note it enables features rather than guaranteeing them.
Template for an “AI-citable” content block (pattern)
External GEO: LLMs are often used to generate variants (rewrite content, insert citations, add stats). The GEO research itself uses a large language model to apply GEO methods to source content, indicating a pragmatic “LLM as content transformation engine” approach.
Internal GEO: prompts and tuning control whether your system cites, how it grounds, and how it refuses unsafe requests. Instruction-following via human feedback improves truthfulness and reduces toxic outputs, which is directly aligned with safe grounded assistants.
Best practices
Use evidence-first transformations (citations/quotes/stats) before stylistic rewriting.
Adopt “query fan-out thinking”: build pages that cover clusters of subquestions so engines can assemble multi-source answers without excluding you.
Keep transformations non-adversarial: the GEO framing explicitly contrasts itself with adversarial manipulation approaches.
Common pitfalls
Automating citation insertion without provenance tracking (you will lose trust and may create legal/compliance exposure).
Optimising for a single engine’s quirks instead of robust evidence signals that generalise.
Decision criteria
If your content changes frequently: prefer templates, structured sections, and automated provenance checks over manual longform rewrites (update cadence unspecified).
If you are in a regulated vertical: treat quotation/statistics tactics as “requires governance” rather than “quick win” (regulatory context unspecified).
The GEO research introduces two central visibility metrics:
They evaluate on GEO-bench (10k queries, diverse domains/intents) and report best methods improving ~41% (PAWC) and ~28% (Subjective Impression) over baseline in the benchmark setting; in a real-engine evaluation using Perplexity, best methods improve ~22% (PAWC) and ~37% (Subjective Impression).
For internal GEO (your system), you typically need both retrieval metrics and generation metrics. RAGAs is a reference-free evaluation framework designed to score RAG pipelines on retrieval and generation quality proxies, explicitly motivated by reducing hallucinations via grounding in a reference database.
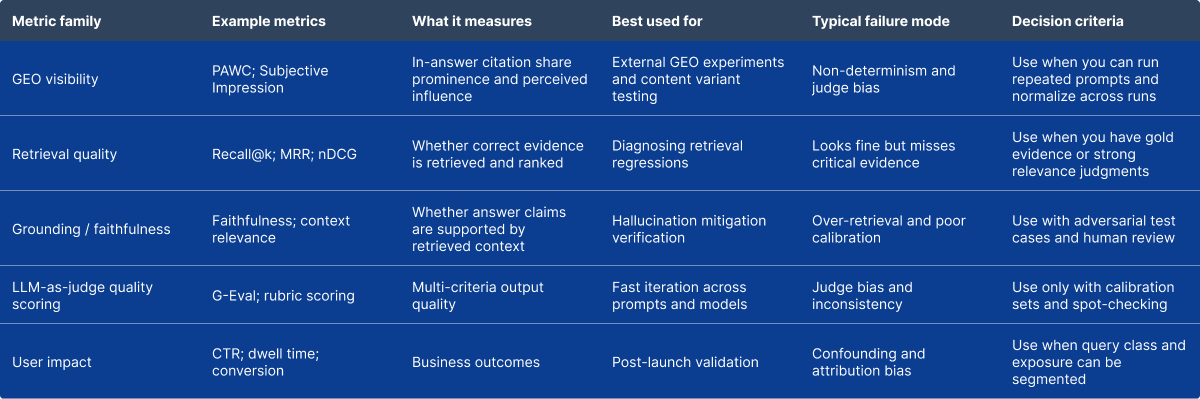
Case study: GEO methods on a 10k-query benchmark
A controlled evaluation reports that adding citations, quotations, and statistics yields strong improvements; best methods improve visibility by ~41% (PAWC) and ~28% (Subjective Impression) over baseline on GEO-bench.
Case study: GEO methods on a deployed generative engine (Perplexity)
The same line of work reports that, on Perplexity, best methods improve ~22% (PAWC) and ~37% (Subjective Impression), supporting generalisability beyond the authors’ simulated setup.
Case study: Production-scale GEO for a visual platform (Pinterest)
A production system frames “visual GEO” as generating intent-aligned textual representations for images, building semantically coherent collection pages, and constructing authority-aware interlinking. It reports 20% organic traffic growth contributing to multi-million MAU growth, and also reports a 19% improvement in topic-query alignment and 94× lower inference cost than commercial VLM APIs in their deployment context. (Exact baselines, attribution methodology, and experiment design details are partially specified in-paper; interpret as reported outcomes.)
Best practices
Treat evaluation as a product: version your prompt set, metrics, and thresholds; rerun on every major content/pipeline change.
For external GEO, measure both visibility and downstream value to avoid winning citations that do not convert.
Common pitfalls
Using a single-run result as “truth” (variance is real and must be averaged).
Over-relying on LLM judges without calibration, despite known calibration/bias concerns.
Decision criteria
If you cannot support repeated evaluations (cost/latency), start with smaller prompt sets and human scoring on the most valuable queries.
Internal GEO: RAG pipeline essentials
A standard RAG framing: load and prepare data into an index; run user queries against the index to retrieve relevant context; send query + context into the LLM for response generation.
A robust enterprise-grade pipeline typically includes:

Vector storage choices (internal)
Vector database options range from “vectors inside your relational DB” to specialised vector stores. Example capabilities include: pgvector (vector similarity in Postgres), and dedicated stores like Milvus, Weaviate, and Pinecone.
Decision factors include: expected scale, latency SLOs (unspecified), tenancy/isolation needs, operational maturity, and compliance constraints.
Why grounding is non-optional
RAG is motivated as a way to reduce hallucinations by grounding responses in a reference database; however, it requires careful design, since bad retrieval can mislead generation.
Techniques with strong evidence base
Because the user’s jurisdiction and regulatory posture are unspecified, the guidance here is structured around widely used frameworks and EU/UK baselines.
Security threats (LLM apps)
The OWASP Top 10 for LLM applications enumerates risks such as prompt injection, insecure output handling, training data poisoning, and more—useful as a threat-model checklist for internal assistants and content pipelines.
Data protection (UK/EU)
Core GDPR principles emphasise lawfulness, fairness, transparency, and security of processing; UK regulatory guidance provides practical interpretation for AI and data protection.
AI governance (EU AI Act context)
The EU AI Act (Regulation (EU) 2024/1689) establishes a risk-based framework for AI systems. Which obligations apply depends on whether you are a provider, deployer, and whether you use general-purpose models, high-risk systems, etc.—all unspecified here.
Risk management framework
NIST’s AI RMF provides a lifecycle risk framework and has companion guidance for generative AI profiles, useful as a governance scaffold.
For external GEO you must understand two separate concerns:
robots.txt is primarily a crawler traffic management mechanism and is not a security control; compliance depends on crawlers obeying it.
Several major AI ecosystems publish distinct crawler controls (search vs training vs user-triggered fetching), and blocking the wrong one can reduce visibility. Examples include published documentation for search-focused crawlers and opt-out mechanisms, plus a publisher FAQ that explicitly advises allowing a search crawler to be included in summaries/snippets and describes how to track referral traffic.
Separately, some public reporting alleges that undeclared or stealth crawling can occur; treat bot governance as a defence-in-depth topic (robots.txt + rate limits/WAF + monitoring).
What to monitor (minimum viable set)
Tools increasingly provide explicit evaluation workflows (offline and online), dataset-based experiments, and trace review.
The specific tool choice depends on language/cloud constraints (unspecified). The table below is intentionally representative rather than exhaustive.
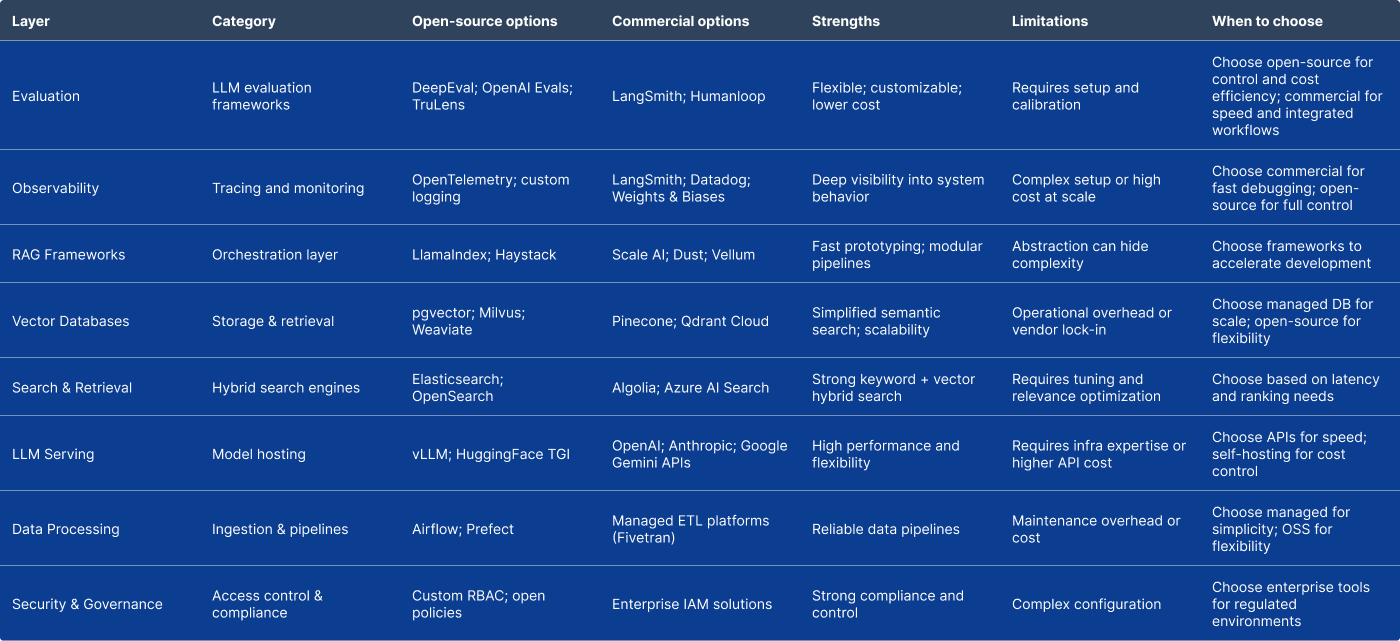
Scalability and cost optimisation patterns
Cost model reality
In many systems, the dominant cost is “tokens × model price” plus retrieval overhead. The Pinterest production case reports very large inference cost reductions vs commercial APIs (94×) in their context, illustrating why engineering for cost can be existential at scale.
Practical levers (stack-agnostic)
Best practices
Enforce a “grounded-by-default” product rule: no citation ⇒ low confidence ⇒ refuse or ask clarifying questions in high-stakes domains.
Make evaluation and monitoring first-class (datasets + offline experiments + online sampling).
Common pitfalls
Scaling content generation without provenance tracking and editorial controls.
Treating robots.txt as a guarantee rather than a signal; it is not an enforcement mechanism.
Decision criteria
If you operate in regulated or privacy-sensitive contexts, bias toward: minimal data retention, strict access control, audit logging, and conservative model behaviours (exact requirements are jurisdiction- and use-case-specific and therefore unspecified).
Checklist: external GEO (public website)
Checklist: internal GEO (build a reliable assistant)
Generative Engine Optimisation is not an extension of SEO.
It is a fundamentally different optimisation problem — one where visibility is no longer determined by ranking positions, but by whether your content is selected, trusted, and used as evidence inside generated answers.
This shift has three practical implications.
First, visibility becomes probabilistic rather than deterministic.
You are not competing for a position, but for inclusion in a synthesis process. This requires thinking in terms of evidence, authority, and coverage — not just keywords.
Second, content becomes infrastructure.
Pages are no longer endpoints; they are components of a system that generative engines query, decompose, and recombine. Structure, clarity, and attribution are no longer optional — they are prerequisites for participation.
Third, optimisation becomes continuous.
Because generative systems evolve, query patterns shift, and outputs vary, GEO cannot be “solved” once. It must be measured, tested, and iterated as an ongoing capability.
For organisations, this creates a clear divide.
Those who treat GEO as a tactical add-on will see diminishing returns, as traditional optimisation approaches fail to translate into generative visibility.
Those who treat GEO as a system — combining measurement, content engineering, retrieval understanding, and iterative improvement — will become part of how answers are constructed.
In a world where users increasingly consume answers instead of links, being part of the answer is the only visibility that matters.


 EN
EN
 DE
DE


